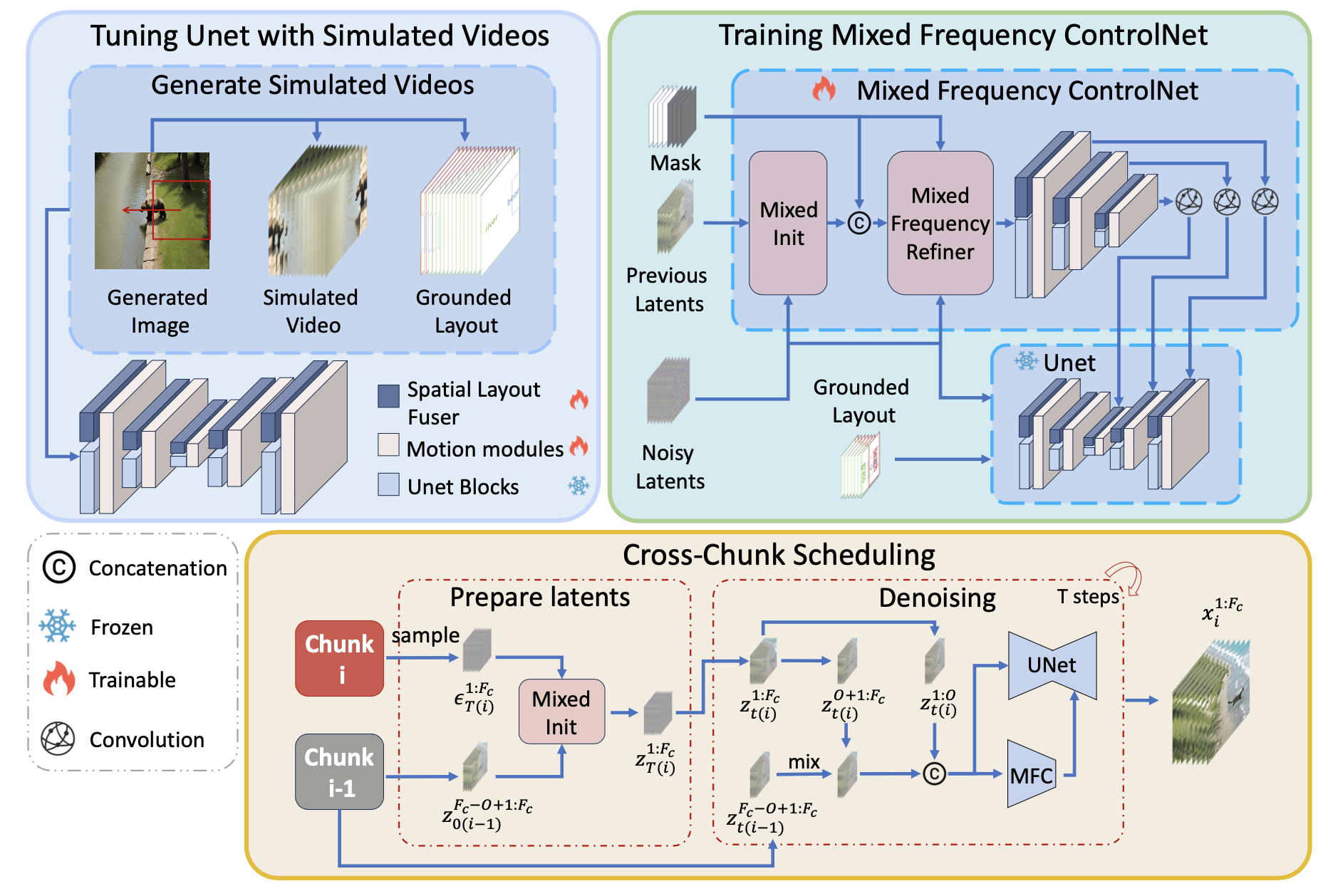
With the development of diffusion models, text-to-video generation has recently received significant attention and achieved remarkable success. However, existing text-to-video approaches suffer from the following weakness: i) they fail to control the trajectory of the subject as well as the process of scene transformations; ii) they can only generate videos with limited frames, failing to capture the whole transformation process. To address these issues, we propose the model named ScenarioDiff, which is able to generate longer videos with scene transformations. Specifically, we employ a spatial layout fuser to control the positions of subjects and the scenes of each frame. To effectively present the process of scene transformation, we introduce mixed frequency controlnet, which utilizes several frames of the generated videos to extend them to long videos chunk by chunk in an auto-regressive manner. Additionally, to ensure consistency between different video chunks, we propose a cross-chunk scheduling mechanism during inference. Experimental results demonstrate the effectiveness of our approach in generating videos with dynamic scene transformations.
 A person is riding a horse under the mountain from right to left.
A person is riding a horse under the mountain from right to left.
 A bird flies around many branches.
A bird flies around many branches.
 Some moose are walking in a meadow under the aurora borealis.
Some moose are walking in a meadow under the aurora borealis.
 A duck is swimming in the pool and then walks ashore.
A duck is swimming in the pool and then walks ashore.
 A tornado swept through, sending two cars into the sky.
A tornado swept through, sending two cars into the sky.
 A boy kicks a ball into a pool of water and a dog runs over to it.
A boy kicks a ball into a pool of water and a dog runs over to it.
 A dog is running from grass to beach.
A dog is running from grass to beach.
 A cloud drifted in from the left and was blown to pieces by the wind after a while.
A cloud drifted in from the left and was blown to pieces by the wind after a while.
 A cat is running from a rock to street.
A cat is running from a rock to street.
 A dog is running from the wheat field to a lake.
A dog is running from the wheat field to a lake.
 A tree in the wind.
A tree in the wind.
 A clownfish goes up and down in the sea.
A clownfish goes up and down in the sea.














